
You may be wondering, "Hey? Why do you give this post a git command as the title?". The reasons's are clicks, views, and sweet-sweet engagement metrics! I hope by using weird idiosyncratic nerdy title will get people to read this post. So, what do I really want to talk about here? You're already 1 minute in reading the post but still has no clue what the heck this is all about. This series of article (yup, there will be more) is written for my Software Engineering course and this one will primarily explain git.
Even if the main driver for me to write this article is this course's credit and the ever aproaching deadline, I will try my best to have something more, something of value that you will only find here and nowhere else (or atleast I'm aware of as I'm writing this article). Oh, and before you are annoyed by this unstructured dialogue and narative writing style, I can only hope that you would bear with me on this wild ride. Deciding which part to tell first is as hard as deciding what I want to write about. So I dont really plan what I'm going to write.
NOTE: This article assume that the reader already has some familiarity with git version control system. You can go read A Tale of Three Trees or my friend's awesome Git Handbook in Indonesian first.
git log
Back to the title. Why this particular command? What does it do? I put this
command because this is my favorite git command, but not the most frequent by
any means. I run git status number of times way more than git log. I check
the number of times I run git status command by running grep "git status" ~/.zsh_history | wc -l. So you can imagine what I'm talking about, you can see
in the nice rendered table below to see how my git commands usage statistics
compare.
| command | n |
|---|---|
| status | 582 |
| add | 266 |
| commit | 168 |
| log | 130 |
| switch | 126 |
| checkout | 119 |
| clone | 72 |
| rebase | 45 |
| pull | 40 |
| reset | 37 |
| fetch | 30 |
| remote | 26 |
| merge | 25 |
| init | 2 |
Interesting to say the least. So it takes a paragraph and a table to explain why
I chose it over any other command and even the new one that just came out, the
git switch command. But wait, I haven't even shown you what this variant with
it's three flag does.
$ git log --all --graph --oneline
The --all flag tells git to show commits from local and every remote branches.
The --graph flag tells git to show commits as graph, connecting commits with
their parrents. And lastly, the --oneline flag will tells git to show commit
logs in oneline pretty format. The result of running this command against this
site's repo is this.
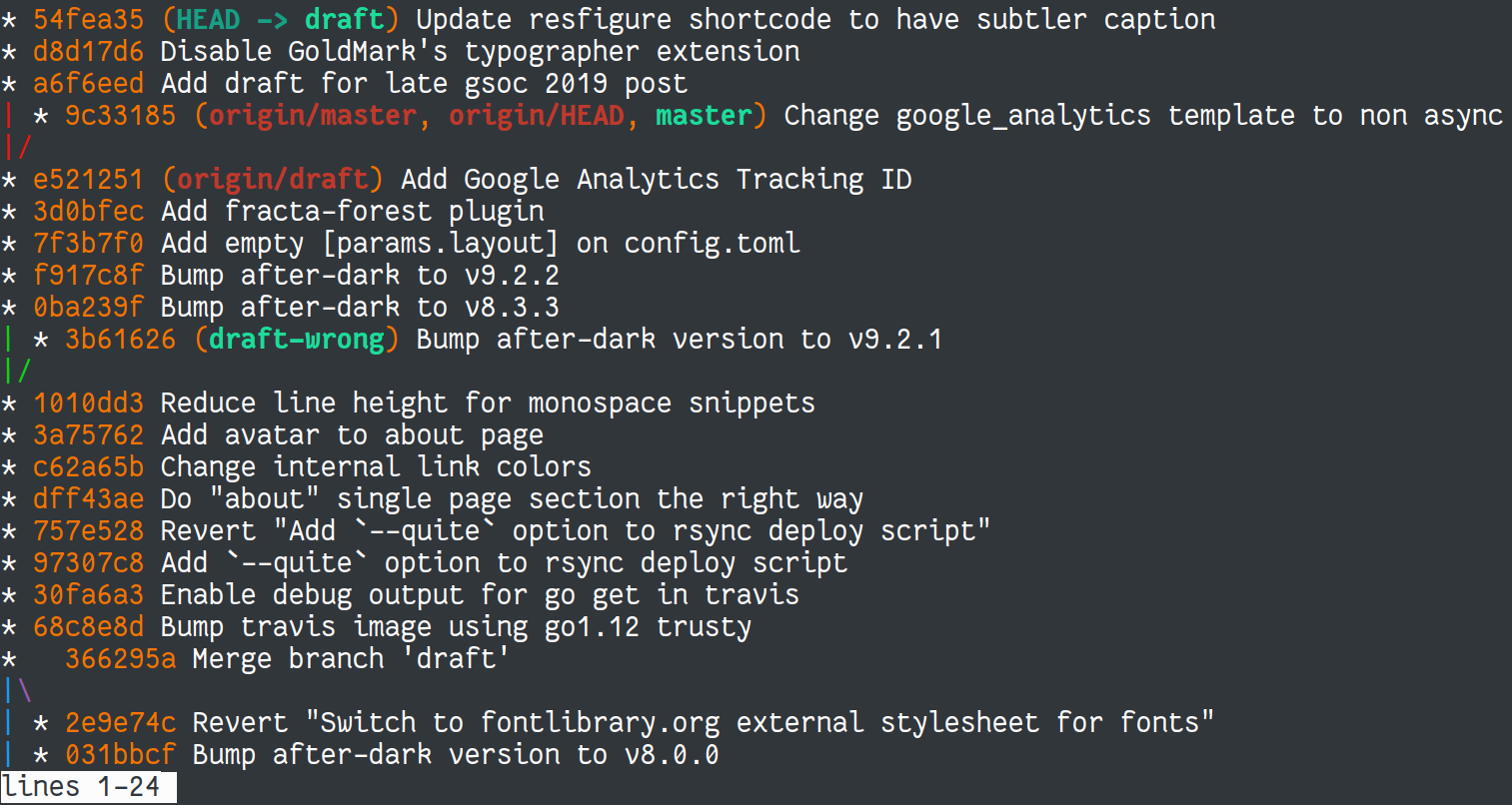
Notice the decorations added after some commit hashes. It will show you not only
your current local branch but all branches tracked by git. This command is very
usefull for me to keep tracks of my local changes against whatever it is in the
origin/master branch or what my team member has pushed to their own branches.
Now you may ask, "Why don't we use the GUI version?". There aren't many real
difference with the GUI version. I use git cli more than any other git client.
Even despite BitBucket and GitLab very beautiful graph view mode. The only
exception is when VS Code's interactive --patch operation comes in really
handy that I will avoid using the cli version.
Here's some of the the honorable mentions. Another variants I want to share with
you is the little git log -<n> version. Not the git log -n <n> variants. It
will saves you a few keystrokes without relying on aliases. Another one I often
check is the git log --show-signature command. In simple explanation, this
command will show you the verified gpg sign of your commit. This one became a
habit since all CNCF organizations have CLA (Contributor License Aggreement)
that mandates every commit to be gpg signed.
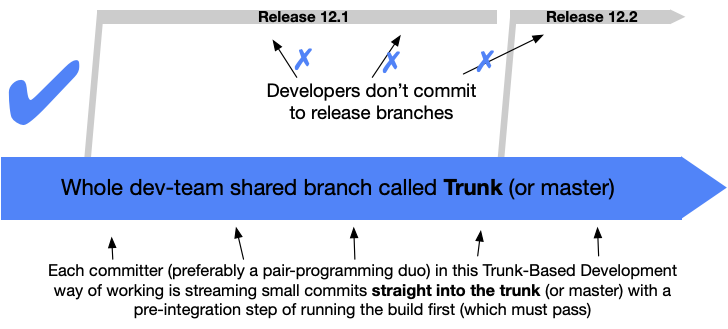
Trunk Based Development
Have I told you how much I love Trunk Based Development compared to the usual Git Flow branching model?
![[REVIEW] Pembahasan Sword Art Online Alicization Episode 4: Tumbangnya Pohon Gigas Cedar](/post/git-log-all-graph-oneline/images/gigas-chedar.webp)
Impressive trunk isn't it? The boring explanation is this. Trunk Based
Development is a source-control branching model, where the main development,
commits, and pull requests occurs at a single branch called the "trunk". This
development model promises avoiding merge hell, broken build, and nicer output
when using the git log --all --graph --oneline (Yup, I do care about this
aspect).
This way feature branches are short-lived and become subject to code reviews and build checking using CI, but not the artifact creation or publication such as pushing to package repository or container registry. One of the arguments is faster feedback loop through code review and faster integration back to the trunk with the use of Feature Flags (Feature Toggle). This is useful to develop large work in progress feature together alongside the other feature in the trunk branch.
Some rule of thumbs of when to integrate Pull/Merge Request to the trunk is:
- It is possible to squash+merge it back to the trunk
- It is already reviewed
- It passed automated tests against the trunk
To avoid breaking changes and conflict, developer will need to learn best ways to sync (integrate) changes from the trunk to feature branch. Learn what rebase is, when to rebase, and how to do it when appropriate. This does demand even more from the developer's skillset besides implementing feature, creating rigorous testing, that is writing maintainable and backward compatible code.
What we actually do
Unfortunately, we dont implement Trunk Based Development in our software engineering course. In my software engineering course we try to implement SCRUM agile software development methodology. There are some requirements for the scoring system and the lecturer team mandates every group to implement a variant of Git Flow branching model. Our project are split into PBIs (Product Backlog Item). PBI is a unit of tangible progress/product that can be used by the user/client. These PBIs are broken down even more into tasks that can tackled down by one person.
There are a lot of things that don't go with my ideal, there are lots of 'em. I want to stop at the previous sentence, but people won't get what I meant unless I written them down here.
Fear of reverting Merge Request if they don't comply with client's standard? Why bother? This will only apply with breaking changes. Incremental changes doesn't need to be reverted. I want to merge into staging and share my core for all I care.
I want to get rid of feature dependency across PBIs. Why? Each sprint can have multiple PBIs. Previously we work on different PBIs concurrently. We might have done it wrong, though. How about we work on one PBI before moving to another PBI? This way we can implement "small" Trunk Based Development using each PBI's branch as the trunk.
Okay, now you are tired of me ranting here instead of actually giving you content and entertainment. Sorry, this will part will be end soon. I believe there are difference between compromises vs half-assed attempt. So, wish me luck on my compromise attempt.
Git Fundamentals: Anantomy of a commit
Okay, next content. Now lets get to the fundamental. This topic is different
from before that I rarely care about this nitty-gritty details on day-to-day
git commit and git rebase daily routine. However, by understanding this
concept I hope you will gain the so-called mechanical sympathy. Mechanical
Sympathy? What new viral virus is that? I heard this concept for the first time
in an amazing talk by Kurniagusta Dwinto about Advanced jenkins :
Create plugin to auto scale worker agent. Too bad that the slide
doesn't give much exposition about the concept by itself. For now, just swallow
these random quotes as they are.
You don't have to be an engineer to be a racing driver, but you do have to have Mechanical Sympathy.
Jackie Stewart, racing driver
Mechanical sympathy is when you use a tool or system with an understanding of how it operates best. When you understand how a system is designed to be used, you can align with the design to gain optimal performance. For example, if you know that a certain type of memory is more efficient when addresses are multiples of a factor, you can optimize your performance by using data structure alignment.
wa.aws.amazon.com/wat.concept.mechanical-sympathy.en.html
On this take on git fundamentals, I want to try explaining things from top to bottom.
In its simplest form, a commit record a single version of the project directory.
We can identify versions using their commit hash. The hashes might look alike to
this f4f78b319c308600eab015a5d6529add21660dc1. Hashes like this is generated
using SHA-1 algorithm. Now, this might make you wonder what are the inputs for
the commit hash? This pseudocode below might give you some idea.
sha1(
commit message => "second commit"
committer => Christoph Burgdorf <christoph.burgdorf@gmail.com>
commit date => Sat Nov 8 11:13:49 2014 +0100
author => Christoph Burgdorf <christoph.burgdorf@gmail.com>
author date => Sat Nov 8 11:13:49 2014 +0100
tree => 9c435a86e664be00db0d973e981425e4a3ef3f8d
parents => [0d973e9c4353ef3f8ddb98a86e664be001425e4a]
)
This pseudocode is borrowed from here. As we can see, besides
the project directory, represented by tree, git also record other metadata
such as commit message to form the commit object, that generate the commit hash.
Are they all? Oh no, I dont think they are all. Remember the gpg signed commit I mentioned above? That's another input for the sha1 hash. However, I dont know the complete list of input to the sha1 hash. Of course, you are free to browse the git repository to uncover the truth :)
Next thing I want to highlight is the parents and tree fields. I'll tell you
this so you give them some thoughts beforehand. parents field refers to the
parrent commits. This field formed the parrent relationship that makes up git's
tree of commits. I wont go into detail about this tree and branching topic,
because what I want to focus on here is about the individual commit.
This lead us to the next topic about the previously mentioned tree field. The
project directory's tree object is represented similaryly to commit object, as
SHA-1 hash. You can imagine the tree object as a list of child items identified
using their sha-1 hash and name. The child items can be another tree object
or a blob object. A blob object simply holds the content of a file tracked by
git. The image below illustrates the relationships between commit, tree, and
blob objects.
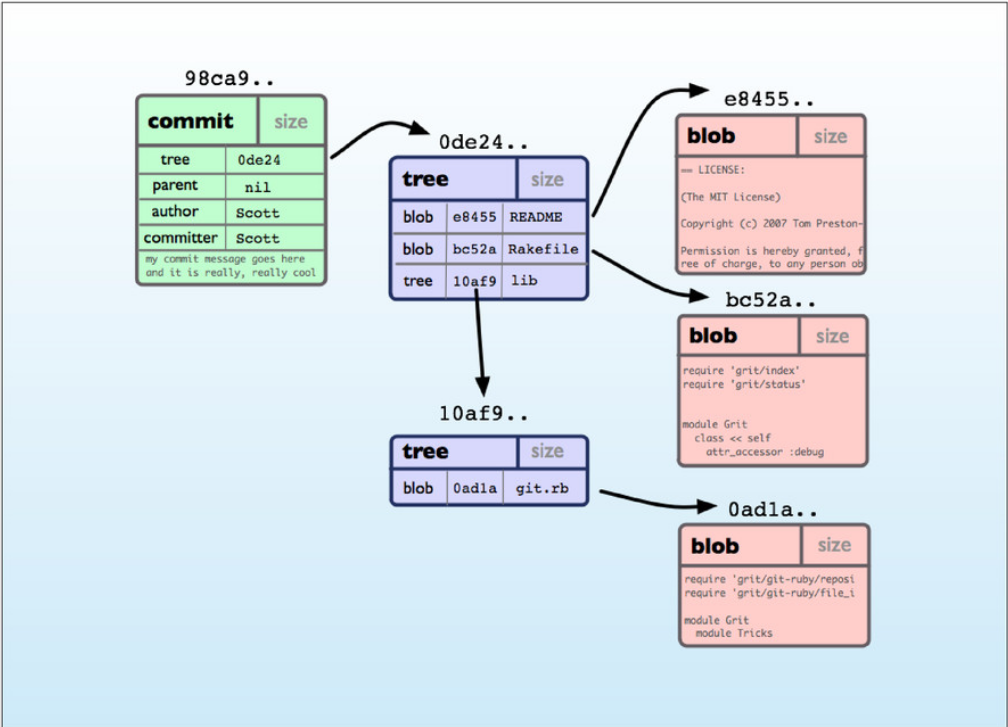
The tree object's hash of hashes shows git's characteristic of storing each commit's state of directory instead of changes. This is done in fairly efficient manner by only storing the changed objects. However, we can also imagine that git will suffer from many small edits in one huge file because it stores a blob object content in its entirety. Thus, each small change demand git to store a new blob object with around the same length even if the change is very minor. Its actually a good practice to split your source code into sensible length so this doesn't happen. But, not everyone can do so for their use case. This problem may arise when people use git for other use case where git is poorly designed such as storing game development assets, or deployment pattern where build artifacts is stored in git repository.
Another opinion of mine that I would like to explain here is the reason why I
prefer rebase compared to merge commit. Its because of git's nature of storing
project directory state in the merge commit. The merged result is often taken
for granted and overlooked. This makes merge commit with conflict resolution
also overlooked by the same people who overlooked automatic merge commit. Sure,
the automatic merge algorithm doesn't try to be too smart and gives us back the
responsibility as soon as conflict is detected. But, please be sure to pay
the same amount of attention a normal commit get to a merge one. This can be
done by simply rewording the commit message from the default "Merge branch
'branch-name'" to give it more attention or by avoiding merge commit
altogether. My final would be to use both sensibly, so your git log --all --graph --oneline output will look beautiful and readable.
Closing
Congratulations, You reached the end! I have to summon a great deal of effort fighting my procrastination to finish this in a way that I like. I also want to thank Leonardo because this article (or random ramblings) is heavliy inspired from his Git Fundamental and Trunk-based Development online class. If you want more thorough explanation about those topics, go check him out.